校園電表計費系統的管理優勢與解決的后勤問題
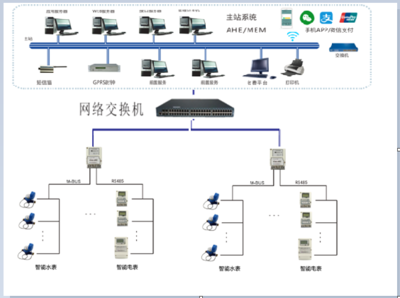
隨著校園規模的擴大和能源管理的精細化需求,傳統人工抄表與電費分攤方式已難以滿足現代學校后勤管理的要求。校園電表計費系統的引入,有效解決了后勤管理中的多個核心問題,提升了管理效率和服務水平。
- 解決了電費計量不精確的問題:傳統人工抄表易出現誤差、漏抄或數據延遲,導致電費分攤不公平,引發師生矛盾。計費系統通過智能電表實時采集數據,自動計算用電量,確保計費精準透明,減少了糾紛。
- 優化了能源消耗管理:系統可實時監測各區域(如教室、宿舍、辦公室)的用電情況,識別高能耗點,幫助后勤部門制定節能策略。例如,通過數據分析關閉非必要用電設備,降低整體電費支出,促進綠色校園建設。
- 提升了管理效率與自動化水平:人工抄表和費用核算耗時耗力,計費系統實現了自動化數據采集、賬單生成和費用通知,減少后勤人員工作量。同時,系統支持在線支付和查詢功能,方便師生自主管理,減輕后勤服務壓力。
- 增強了安全與故障響應能力:系統具備用電異常監測功能,如過載或漏電,可及時報警并自動切斷電源,預防電氣火災等安全事故。后勤部門能快速定位故障點,提高應急處理效率,保障校園用電安全。
- 促進了資源公平分配與成本控制:在宿舍或實驗室等場所,系統可根據實際用電量收費,避免“大鍋飯”式分攤,鼓勵節能行為。后勤部門還能通過數據分析預測用電趨勢,合理分配預算,控制運營成本。
- 支持數據驅動決策:系統生成詳細的用電報告和統計圖表,為后勤管理提供數據支持,幫助學校制定長期能源政策,如優化用電時段或升級設施,實現科學化管理。
校園電表計費系統不僅解決了計費不準、效率低下和安全風險等傳統問題,還推動了后勤服務的數字化和智能化轉型,為學校節約資源、提升師生滿意度奠定了堅實基礎。
如若轉載,請注明出處:http://www.cenglshen3.cn/product/13.html
更新時間:2026-06-19 06:00:23