黨建引領促服務 聯建共建譜新篇——后勤黨支部與佛山聯通黨支部簽約共聯共建助力單位后勤管理服務提質增效

為深入貫徹落實新時代黨的建設總要求,積極探索基層黨建工作新思路、新模式,以高質量黨建引領保障高質量發展,[請在此處填寫你單位名稱,例如:XX大學/XX集團]后勤黨支部與中國聯通佛山分公司(以下簡稱“佛山聯通”)相關黨支部隆重舉行了結對共聯共建簽約儀式。此次共建旨在通過組織聯建、資源聯享、服務聯動、發展聯促,共同提升黨建工作水平,并將黨建優勢轉化為推動單位后勤管理服務現代化、智慧化、精細化的強大動力。
簽約儀式在莊嚴而熱烈的氛圍中進行。雙方黨支部負責人分別介紹了各自支部的基本情況、黨建工作特色以及業務發展概況,并圍繞共建目標、共建內容與共建機制進行了深入交流和探討。雙方一致認為,此次共建是推動黨建工作與中心業務深度融合的有益嘗試。后勤部門承擔著保障單位日常運行、服務師生員工或干部職工的重要職責,其管理服務水平直接關系到單位的整體效能與和諧穩定。而佛山聯通作為本地重要的通信服務與信息化解決方案提供商,在5G、物聯網、云計算、大數據等新型信息技術領域擁有深厚的技術積累和豐富的應用經驗。雙方的合作具有高度的互補性與廣闊的實踐空間。
根據共建協議,雙方將重點在以下幾個方面開展深度合作:
一、組織建設互促,夯實戰斗堡壘
定期聯合開展主題黨日活動、專題黨課學習、黨員教育培訓等,交流黨建工作經驗,共享優秀案例,共同探索“智慧黨建”新路徑,不斷提升黨支部的組織力、凝聚力和戰斗力,打造政治功能強、支部班子強、黨員隊伍強、作用發揮強的“四強”黨支部。
二、黨員隊伍互動,激發先鋒活力
建立黨員交流機制,互派黨員骨干進行短期學習、掛職鍛煉或參與重點項目,在急難險重任務中錘煉黨性、提升能力。聯合組建“黨員先鋒隊”或“志愿服務隊”,圍繞后勤服務中的難點、堵點問題,開展技術攻關、流程優化、便民服務等活動,充分發揮黨員的先鋒模范作用。
三、優勢資源互享,賦能智慧后勤
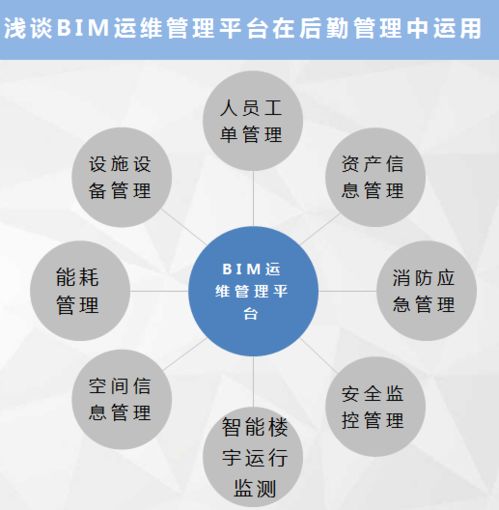
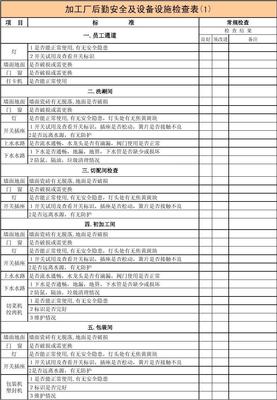
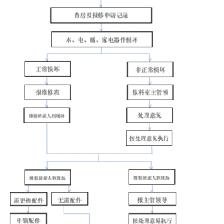
依托佛山聯通在信息通信技術方面的優勢,共同探索“5G+智慧后勤”創新應用場景。例如,在能源管理、安防監控、設備運維、樓宇自控、餐飲服務、物業服務等領域,引入物聯網感知、大數據分析、AI智能識別等技術,構建集“監、管、控、服”于一體的智慧后勤管理平臺,實現后勤資源的動態配置、運行狀態的實時監測、服務需求的精準響應和安全風險的智能預警,大幅提升管理效率、服務質量和安全保障能力。
四、服務發展互贏,提升保障效能
聚焦單位后勤服務的實際需求,聯合開展專項調研與課題研究,共同制定后勤信息化、標準化建設方案。佛山聯通可提供定制化的通信服務、網絡保障及信息化解決方案,助力后勤部門打造更高效、更便捷、更人性化的服務環境。后勤部門也可為佛山聯通的技術落地、產品優化提供真實的業務場景和應用反饋,實現雙向賦能、合作共贏。
五、廉潔文化互建,筑牢思想防線
攜手開展黨風廉政宣傳教育,共享廉潔文化資源,共同營造風清氣正、務實擔當的工作氛圍。在合作項目中,明確權責邊界,規范工作流程,加強監督管理,確保共建活動健康、有序、廉潔開展。
此次后勤黨支部與佛山聯通黨支部的“聯姻”,是黨建引領業務發展的生動實踐,標志著單位后勤管理服務向著數字化、網絡化、智能化轉型邁出了堅實的一步。雙方將以共建協議為藍圖,以解決實際問題、提升服務品質為導向,定期評估共建成效,不斷豐富共建內涵,確保共建活動取得實實在在的成果,努力打造可復制、可推廣的“黨建+業務”融合共建樣板,為單位的穩健運行和高質量發展提供更加堅實可靠的后勤服務保障,共同譜寫攜手共進、互利共贏的新篇章。
如若轉載,請注明出處:http://www.cenglshen3.cn/product/57.html
更新時間:2026-06-19 00:08:37